此文待重构。
JDBC
什么是 JDBC ?
JDBC(Java Data Base Connectivity,java数据库连接)是一种用于执行 SQL 语句的 Java API(Application Programming Interface),可以为多种关系数据库提供统一访问,它由一组用 Java 语言编写的类和接口组成。JDBC 提供了一种基准,据此可以构建更高级的工具和接口,使数据库开发人员能够编写数据库应用程序,是连接数据库和Java应用程序的纽带。
简单说它就是 JAVA 与数据库的连接的桥梁或者插件,用 JAVA 代码就能操作数据库的增删改查、存储过程、事务等。
通过 JDBC,我们使用 JAVA 语言就能连接到数据库,之后创建 SQL 或者 MySQL 语句;执行后能对数据库进行 CRUD 操作。
JDBC API 介绍及接口
JDBC API 主要做三件事:
- 与数据库建立连接
- 发送 SQL 语句
- 得到处理结果
提供的接口包括:
- JAVA API:提供对 JDBC 的管理链接
- JAVA Driver API:支持 JDBC 管理到驱动器连接
DriverManager:这个类管理数据库驱动程序的列表,查看加载的驱动是否符合JAVA Driver API的规范,装载驱动程序,并为创建新的数据库连接提供支持。
Connection:与数据库中的所有的通信是通过唯一的连接对象。该类负责连接数据库并担任传送数据的任务。
Statement:把创建的SQL对象,转而存储到数据库当中。该类由Connection产生,负责执行SQL语句。
ResultSet:它是一个迭代器,用于检索查询数据。该类负责保存和处理Statement中心执行后所产生的查询结果。
JDBC 访问数据库的基本步骤
见代码及注释:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19//1.载入JDBC驱动程序
Class.forName("JDBC驱动类的名称");
//2.与数据库建立连接
Connection con= DriverManager.getConnection(数据库连接字符串,数据库用户名,密码);
//3.发送SQL语句,并得到返回结果
Statement st = con.createStatement();//请使用它更安全的子类,防止SQL注入攻击
ResultSet rs = st.executeQuery("sql语句");
//4.处理返回结果
while(rs.next()){
通过循环取出结果
}
//5.关闭连接
rs.close();
st.close();
con.close();
JDBC 通俗化理解
JDBC 就是我们想要用 JAVA 语言操作数据库的一个东东。
JDBC 的连接类似于两个岛屿的链接,假如现在要你在两岛之间运送货物,那么如何将一批货物从这个岛的一边运向另一个岛,又从那个岛运货回来呢?
很简单,我们需要搭桥,那么Connection con就是这个桥。
你要搭桥肯定需要工具和材料,有工具和材料才能建桥,那么驱动类、url就是搭桥的工具和材料,不同的数据库驱动和url也不同。
桥搭好了,像上高速一样你还需要携带通行证才能过桥,那么通行证的姓名和号码就是root和password,也就是连接数据库的账号和密码。
你还不能去运货,还需要一辆车,那么这辆车就是Statement(SQL 语句执行对象),拥有了这些后你就可以运货去河对岸了。
当货物返回来了,那么就需要卸货了,这个功能可以交给ResultSet rs来做,rs会通过rs.next()这个方法将货物卸下来。
当这些事情做完了后,你就需要将con、rs、st这三个对象回收了,不然别人乱用你的,怎么办?
如下图,不同的数据库 JDBC 驱动不同,连接的数据库也不同,我们通过 JDBC 建立了 JAVA 和数据库之间的桥梁,车我就不画了。。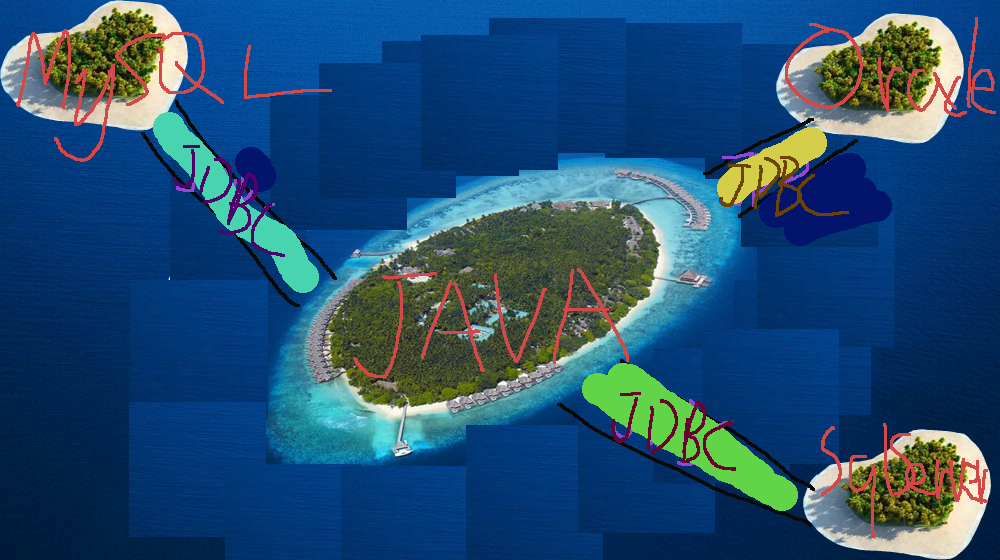
数据源(数据库连接池)
什么是数据源?
In software engineering, a connection pool is a cache of database connections maintained so that the connections can be reused when future requests to the database are required. Connection pools are used to enhance the performance of executing commands on a database. Opening and maintaining a database connection for each user, especially requests made to a dynamic database-driven website application, is costly and wastes resources. In connection pooling, after a connection is created, it is placed in the pool and it is used again so that a new connection does not have to be established. If all the connections are being used, a new connection is made and is added to the pool. Connection pooling also cuts down on the amount of time a user must wait to establish a connection to the database.
翻译:在软件工程中,连接池是一种用于维持所连数据库的缓存机制,以便在将来对数据库的请求需要时可以重用连接。 连接池可以提高在数据库上执行命令的性能。我们知道,为每个用户打开和保持数据库连接(特别是对动态数据库驱动的网站应用程序的请求),代价高昂且浪费资源。而使用连接池,在创建连接之后,将其放入池中,当需要时取出来使用它,使用完又放回去,以不必建立新连接。如果所有的连接都被使用,就再创建一个新的连接并增加到连接池中。
种类
数据源的种类有很多,下面为比较常见的:
- DBCP 连接池
- C3P0 连接池
- Druid 连接池
- HikariCP 连接池
如何使用连接池?
其实和 JDBC 的使用差不多,只是现在驱动、url、用户名和密码交由连接池管理,由它去创建连接。
示例如下:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
public void testC3P0() {
//1.获取 c3p0 连接池
ComboPooledDataSource c3p0 = new ComboPooledDataSource();
//2.设置相关属性
c3p0.setDriverClass();
c3p0.setJdbcUrl();
c3p0.setUser();
c3p0.setPassword();
//2.1还可以设置别的参数
c3p0.setMaxPoolSize();
c3p0.setCheckoutTimeout();
//3.获取连接
Connection connection = c3p0.getConnection();
//4.获取语句执行平台
Statement statement = connection.createStatement();
String sql = "";
//5.查询结果集
ResultSet result = statement.executeQuery(sql);
/**
* 也可以使用防止SQL注入的prepareStatement
* PreparedStatement pst = connection.prepareStatement(sql);
* ResultSet resultSet = pst.getResultSet();
*/
//6.遍历结果集
while (result.next()) {
result.getInt()
}
//7.优雅地关闭连接(将连接放回到数据库连接池中)
connection.close();
}
public void testDruid() {
//1.获取druid连接池
DruidDataSource dds = new DruidDataSource();
//2.设置相关属性
dds.setDriverClassName();
dds.setUrl();
dds.setUsername();
dds.setPassword();
//2.1还可以设置别的参数
dds.setMaxActive();
dds.setLoginTimeout();
//3.获取连接
DruidPooledConnection connection = dds.getConnection();
//4.获取语句执行平台
Statement statement = connection.createStatement();
//5.查询结果集
String sql = "";
ResultSet resultSet = statement.executeQuery(sql);
/**
* 也可以使用防止SQL注入的prepareStatement
* PreparedStatement pst = connection.prepareStatement(sql);
* ResultSet resultSet = pst.getResultSet();
*/
//6.遍历结果集
while (resultSet.next()) {
resultSet.getInt() + resultSet.getString();
}
//7.优雅地关闭连接(将连接放回到数据库连接池中)
connection.close();
}
具体的参数一般都放在配置文件中,可以防止硬编码。
DBUtils 工具类
什么是 DBUtils?
DBUtils是 JDBC 的简化开发工具包,若想使用需要加入commons-dbutils-x.x.jar依赖(x.x为版本号)
DBUtils具有以下特点:
- 小巧简单实用。
- 封装了对JDBC的操作,简化了其操作,可以减少代码量。
为什么使用 DBUtils?
如果只使用 JDBC 进行开发,我们会发现程序中会存在过多冗余代码,为了简化 JDBC 开发,可以采用apache commons组件的一个成员:DBUtils。
核心 API
Dbutils具有 3 个核心类:
QueryRunner:提供对 SQL 语句操作的 APIResultSetHandler接口:用于定义select操作后,以何种方式封装的结果集DbUtils类:一个工具类,定义了关闭资源与事务处理的方法
QueryRunner
什么是QueryRunner?让我们来看一下官方文档的解释:
Executes SQL queries with pluggable strategies for handlling ResultSets.This class is thread safe.
翻译过来就是:使用可插入策略执行 SQL 查询以处理 ResultSet。这个类是线程安全的。
QueryRunner的构造方法:
QueryRunner()QueryRunner(boolean pmdKnowdBroken)QueryRunner(DataSource ds)QueryRunner(DataSource ds, boolean pmdKnownBroken)
第二个和第四个不用太多关心,和Oracle有关,我们主要使用第一个和第三个方法,无参构造和有参构造(带数据源的)的区别是无参后面需要传Connection连接,而有参构造不需要,因为你传了DataSource后DBUtils底层会自动维护连接Connection。
该类的普通方法如下表:
| 返回类型 | 方法及说明 |
|---|---|
int[] |
batch(Connection conn, String sql, Object[][] params)Execute a batch of SQL INSERT, UPDATE, or DELETE queries. |
int[] |
batch(String sql, Object[][] params)Execute a batch of SQL INSERT, UPDATE, or DELETE queries. |
int |
execute(Connection conn, String sql, Object... params)Execute an SQL statement, including a stored procedure call, which does not return any result sets. |
<T> List<T> |
execute(Connection conn, String sql, ResultSetHandler<T> rsh, Object... params)Execute an SQL statement, including a stored procedure call, which returns one or more result sets. |
int |
execute(String sql, Object... params)Execute an SQL statement, including a stored procedure call, which does not return any result sets. |
<T> List<T> |
execute(String sql, ResultSetHandler<T> rsh, Object... params)Execute an SQL statement, including a stored procedure call, which returns one or more result sets. |
<T> T |
insert(Connection conn, String sql, ResultSetHandler<T> rsh)Execute an SQL INSERT query without replacement parameters. |
<T> T |
insert(Connection conn, String sql, ResultSetHandler<T> rsh, Object... params)Execute an SQL INSERT query. |
<T> T |
insert(String sql, ResultSetHandler<T> rsh)Executes the given INSERT SQL without any replacement parameters. |
<T> T |
insert(String sql, ResultSetHandler<T> rsh, Object... params)Executes the given INSERT SQL statement. |
<T> T |
insertBatch(Connection conn, String sql, ResultSetHandler<T> rsh, Object[][] params)Executes the given batch of INSERT SQL statements. |
<T> T |
insertBatch(String sql, ResultSetHandler<T> rsh, Object[][] params)Executes the given batch of INSERT SQL statements. |
<T> T |
query(Connection conn, String sql, Object[] params, ResultSetHandler<T> rsh)Deprecated. Use query(Connection,String,ResultSetHandler,Object...) instead |
<T> T |
query(Connection conn, String sql, Object param, ResultSetHandler<T> rsh)Deprecated. Use query(Connection, String, ResultSetHandler, Object...) |
<T> T |
query(Connection conn, String sql, ResultSetHandler<T> rsh)Execute an SQL SELECT query without any replacement parameters. |
<T> T |
query(Connection conn, String sql, ResultSetHandler<T> rsh, Object... params)Execute an SQL SELECT query with replacement parameters. |
<T> T |
query(String sql, Object[] params, ResultSetHandler<T> rsh)Deprecated. Use query(String, ResultSetHandler, Object...) |
<T> T |
query(String sql, Object param, ResultSetHandler<T> rsh)Deprecated. Use query(String, ResultSetHandler, Object...) |
<T> T |
query(String sql, ResultSetHandler<T> rsh)Executes the given SELECT SQL without any replacement parameters. |
<T> T |
query(String sql, ResultSetHandler<T> rsh, Object... params)Executes the given SELECT SQL query and returns a result object. |
int |
update(Connection conn, String sql)Execute an SQL INSERT, UPDATE, or DELETE query without replacement parameters. |
int |
update(Connection conn, String sql, Object... params)Execute an SQL INSERT, UPDATE, or DELETE query. |
int |
update(Connection conn, String sql, Object param)Execute an SQL INSERT, UPDATE, or DELETE query with a single replacement parameter. |
int |
update(String sql)Executes the given INSERT, UPDATE, or DELETE SQL statement without any replacement parameters. |
int |
update(String sql, Object... params)Executes the given INSERT, UPDATE, or DELETE SQL statement. |
int |
update(String sql, Object param)Executes the given INSERT, UPDATE, or DELETE SQL statement with a single replacement parameter. |
简单来讲也就 2 个方法,一个query()方法用于 SQL 语句的查询,一个update()方法用于 SQL 语句的增加,更新(修改),删除。
返回值根据参数的不同返回结果不同,参数一般都用ResultHandler类,
ResultHandler
什么是ResultHandler呢?
从字面翻译来看就是处理结果集,它是一个接口,具有许多实现类。
我们知道在执行select语句之后得到的是ResultSet,然后还需要对其进行转换以得到最终想要的数据。你可能想把ResultSet的数据放到一个List中,也可能想把数据放到一个Map中,或是一个JavaBean中。
而DBUtils提供了一个ResultSetHandler接口,它是用来将原生 JDBC 的ResultSet转换成目标类型的工具。你也可以自己去实现这个接口,把ResultSet转换成你想要的类型。
DBUtils提供了很多个ResultSetHandler接口的实现类,这些实现类基本已经足够你使用了。
下表为ResultHandler的实现类。
| 实现类 | 说明 |
|---|---|
| ArrayHandler | 将结果集中的第一条记录封装到一个Object[]数组中,数组中的每一个元素就是这条记录中的每一个字段的值 |
| ArrayListHandler | 将结果集中的每一条记录都封装到一个Object[]数组中,将这些数组在封装到List集合中。 |
| BeanHandler | 将结果集中第一条记录封装到一个指定的JavaBean中 |
| BeanListHandler | 将结果集中每一条记录封装到指定的javaBean中,将这些javaBean在封装到List集合中 |
| ColumnListHandler | 将结果集中指定的列的字段值,封装到一个List集合中 |
| ScalarHandler | 它是用于单数据。例如select count(*) from 表操作 |
| MapHandler | 将结果集第一行封装到Map集合中,Key 列名, Value 该列数据 |
| MapListHandler | 将结果集第一行封装到Map集合中,Key 列名, Value 该列数据,Map集合存储到List集合 |
参考
- 维基百科